바이브컴퍼니(이하 바이브)가 자체 sLLM(초거대언어모델) 바이브GeM의 다음 버전인 생성형 AI 파운데이션 모델 ‘바이브GeM 2’를 오픈소스로 공개했다.
바이브GeM 2는 총 2.5조 개의 토큰을 사전 학습한 파라미터 14B(140억 개)모델로, 기존 모델 대비 한 층 업그레이드된 성능을 드러냈다. 기존 모델에서 코딩, 번역, 멀티턴(Multi-turn) 대화까지 추가로 지원되는 것이 특징이다. 또한 이전보다 적은 메모리를 사용해 더욱 더 빠른 생성이 가능해졌다.
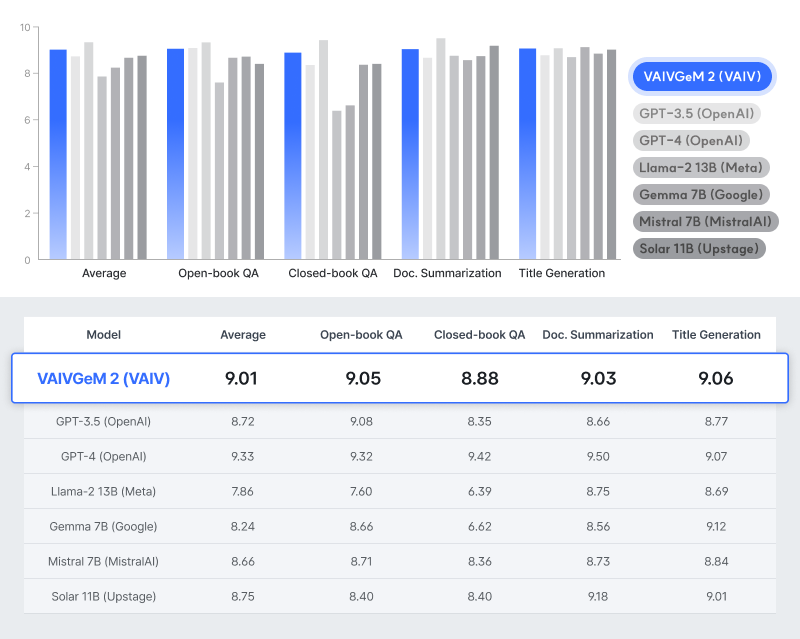
특히 한국어 작업 성능 미세조정(Fine-tuning) 실험 결과에서 GPT 3.5보다 높은 성능을 보이는 것으로 나타났다. 바이브는 AI 응용 시 가장 많이 활용되는 Open-book QA(오픈북 질의응답), Closed-book QA(클로즈드북 질의응답), Doc. Summarization(문서 요약), Title Generation(제목 생성) 등 4가지 주요 작업(Task)을 기준으로 테스트를 진행한 결과, 메타의 라마2, 구글의 젬마, 업스테이지의 솔라 등 기존에 오픈소스로 공개된 sLLM 중 가장 뛰어난 성능을 보였다. 해당 테스트는 각 베이스 모델에 동일한 데이터를 기반으로 미세조정을 실시한 후, 각 작업 별로 100개의 테스트 샘플에 대해 생성된 답변을 GPT 4를 통해 평가했다.
바이브는 바이브GeM 2의 다른 이름으로 선보인 ‘라미온(Llamion)’을 ‘Open-Ko LLM 리더보드’에도 오픈소스로 공개하며 높은 성능을 인정받았다. Open-Ko LLM 리더보드는 한국지능정보사회진흥원과 허깅페이스가 함께 운영 중인 한국형 LLM 평가 플랫폼으로, 몇 가지 항목을 기준으로 한국어 LLM 모델 평가가 가능하다. 특히 그중에서도 생성형 AI 기술과 밀접한 상관관계가 있는 것으로 간주되는 ‘Ko-MMLU(대규모 다중작업 언어이해력)’ 부분에서는 바이브GeM 2가 1위를 차지했다.
바이브GeM은 바이브가 20년 이상 축적한 NLP(자연어처리) 기술을 토대로 지난해 공개한 자체 sLLM이다. 이를 기반으로 한 다양한 AI 기반 솔루션 및 서비스들을 출시하고 초거대 AI 공급사업자로도 선정돼 국민권익위원회, 조달청, 관세청, 고용노동부, 충남도청 등 많은 공공기관에 성공적인 PoC(기술검증)를 진행한 바 있다.
또한, 바이브는 최근 과학기술정보통신부로부터 생성형 AI 선도인재양성 사업의 주관 기관으로 선정되며 AI 인재 양성에도 앞장서고 있는 만큼, 이번 바이브GeM 2의 공개를 통해 한국의 생성 AI 경쟁력 강화하고 관련 생태계를 조성하는 데 크게 기여할 전망이다.
바이브의 김성언 대표는 “sLLM을 도입하고자 하는 기업 또는 기관들에게 바이브GeM 2는 최고의 선택이 될 것.”이라며 “올해 안에 더 고도화된 바이브GeM 2.5와 바이브GeM 3을 시장에 선보이고 지속적으로 서비스와 솔루션에 반영해 나갈 것.”이라고 말했다.





Leave a Comment