알리바바 클라우드가 AI 기반 영상 생성 모델 ‘Wan2.1’ 시리즈를 오픈소스로 공개했다.
이번에 공개된 모델은 140억(14B) 및 13억(1.3B) 매개변수를 가진 4종으로, 텍스트와 이미지 입력을 기반으로 이미지와 영상을 생성한다. 이 모델들은 알리바바 클라우드의 AI 모델 커뮤니티 ‘모델스코프’와 ‘허깅페이스’에서 다운로드할 수 있다.
Wan2.1 시리즈는 중국어와 영어에서 텍스트 효과를 지원하는 최초의 AI 영상 생성 모델로 알려졌다. 이 모델은 복잡한 움직임 처리, 픽셀 품질 향상, 물리적 원칙 준수, 명령 실행 정확도 최적화 등에서 강점을 보인다.
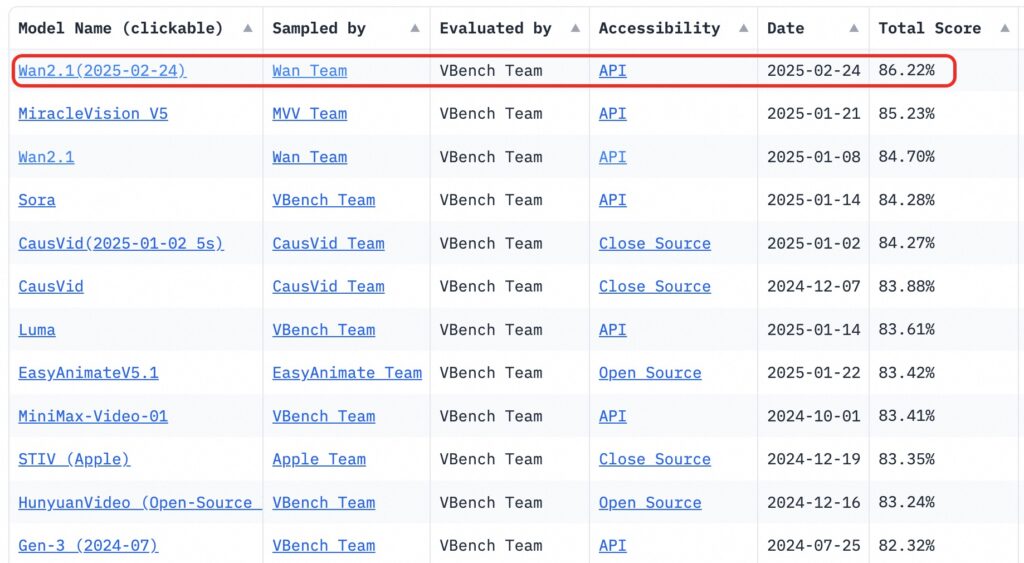
알리바바 클라우드 관계자는 “Wan2.1 시리즈가 영상 생성 모델의 종합 벤치마크인 VBench 리더보드에서 1위를 기록했다”며 “상위 5개 모델 중 유일한 오픈소스 영상 생성 모델”이라고 밝혔다.
VBench에 따르면, Wan2.1 시리즈는 종합 점수 86.22%를 기록하며 움직임의 자연스러움, 공간적 관계, 색상 표현, 다중 객체 상호작용 등 핵심 평가 항목에서 최고 수준의 성능을 보였다.
AI 전문가들은 “영상 생성 AI 모델 훈련에는 막대한 컴퓨팅 자원과 대량의 고품질 학습 데이터가 필요하다”며 “이러한 모델을 오픈소스로 개방하면 AI 활용의 장벽을 낮출 수 있다”고 설명했다.
T2V-14B 모델은 복잡한 동작이 포함된 고품질 영상 생성에 최적화됐으며, T2V-1.3B 모델은 생성 품질과 연산 효율성의 균형을 맞춰 다양한 개발자들에게 적합한 솔루션을 제공한다. 예를 들어, T2V-1.3B 모델은 일반 노트북에서도 480p 해상도의 5초 길이 영상을 약 4분 만에 생성할 수 있다.
I2V-14B-720P 및 I2V-14B-480P 모델은 텍스트 기반 영상 생성뿐만 아니라 이미지 기반 영상 생성 기능도 지원한다. 사용자는 한 장의 이미지와 간단한 텍스트 설명만으로 역동적인 영상 콘텐츠를 제작할 수 있다.
한편, 알리바바 클라우드는 2023년 8월 자체 개발한 대규모 AI 모델 ‘Qwen’을 첫 공개한 바 있다. Qwen 시리즈는 허깅페이스의 오픈 LLM 리더보드에서 지속적으로 최상위권을 유지하며 글로벌 최고 수준의 AI 모델과 경쟁하고 있다.
현재 허깅페이스에서 Qwen 모델을 기반으로 개발된 파생 모델이 10만 개를 돌파해, 전 세계에서 가장 규모가 큰 AI 모델군 중 하나로 자리매김했다고 알리바바 클라우드 측은 전했다.





댓글 남기기