중국 알리바바그룹이 OpenAI의 핵심 딥 리서치 도구와 견줄만한 성능을 갖췄다고 주장하는 오픈소스 인공지능 에이전트를 공개했다.
알리바바 AI 검색 개발팀 통이랩은 화요일 블로그를 통해 이 에이전트가 자사 지도앱 아맵과 AI 법률연구 툴 통이파루이에 적용됐다고 발표했다.
아맵 이용자들은 이제 딥 리서치 에이전트의 웹 검색 기능을 통해 며칠간의 여행 일정을 짤 수 있다. 통이파루이는 에이전트의 연구 기능이 추가되면서 정확한 출처와 함께 판례를 찾는 성능이 크게 개선됐다.
이번 출시는 알리바바의 AI 사업 확장 행보 중 하나다. 최근 2주 사이에만 1조 매개변수 규모의 기본모델 큐원-3-맥스-프리뷰와 더 작지만 성능이 뛰어난 큐원3-넥스트-80B-A3B를 잇달아 내놨다.
딥 리서치 에이전트는 여러 단계를 거쳐 복잡한 웹 검색을 처리하는 AI 도구다. 이 분야 선두주자는 지난 2월 ChatGPT에 탑재된 OpenAI의 딥 리서치다. 구글 딥마인드 등 다른 미국 빅테크들도 비슷한 서비스를 내놓고 있다.
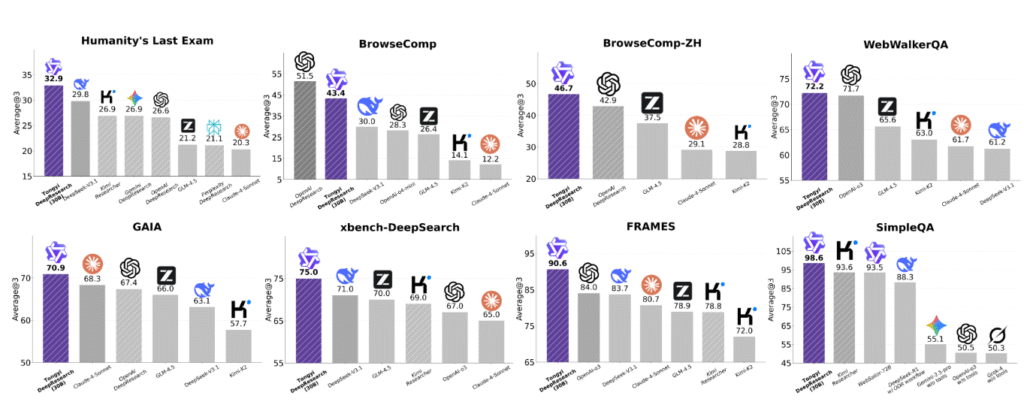
알리바바는 자사 에이전트가 300억 개 매개변수만으로도 미국 경쟁사들 대비 “놀라운 효율성”을 보인다고 강조했다. 이는 미국 딥 리서치 에이전트들의 추정 매개변수보다 훨씬 적은 규모다.
매개변수는 AI 모델의 ‘지능’ 수준을 결정하는 핵심 요소로, 일반적으로 수가 많을수록 성능이 좋지만 그만큼 많은 컴퓨팅 자원을 필요로 한다.
알리바바 자료에 따르면, 새 에이전트는 AI 시스템의 한계를 시험하는 고난도 학술문제 ‘휴머니티스 라스트 엑삼’에서 32.9%를 기록했다. 이는 OpenAI 딥 리서치의 26.6%를 웃도는 수치다. 다만 OpenAI 점수는 올해 초 측정된 것이다.
오픈소스 플랫폼 허깅페이스의 머신러닝 커뮤니티 매니저 아디나 야케푸는 알리바바의 벤치마크 결과를 “대단하다”고 평가했다. 오픈소스로 공개된 뒤 이 에이전트는 플랫폼에서 큰 관심을 끌며 전 세계 개발자들이 활용하고 있다.
UC 버클리 스카이 컴퓨팅 랩의 탄 시준 연구원은 알리바바 에이전트의 우수한 성능과 효율성이 “매우 높은 품질”의 합성 훈련 데이터를 만드는 혁신적 데이터 처리 과정 덕분이라고 분석했다.
합성 훈련 데이터는 실제 데이터가 아닌 AI가 만든 데이터다. 실제 데이터 확보가 어려워지면서 AI 업체들이 합성 데이터 활용을 늘리고 있다.
알리바바는 자사 합성 데이터 기술을 전체 훈련 과정에 적용하고, 훈련 중 생성된 데이터를 사람의 개입 없이 재활용하는 ‘데이터 순환’ 방식을 개발했다고 밝혔다.
개발팀은 “이 방식이 뛰어난 데이터 품질과 대규모 확장성을 동시에 확보하며 모델 성능의 한계를 뛰어넘는다”고 설명했다. 다만 300억 매개변수보다 훨씬 큰 모델에서는 아직 검증되지 않았다고 덧붙였다.
알리바바는 또 12만8천 토큰 길이의 맥락 처리 한계가 복잡한 연구 작업에서는 여전히 제약요소라고 인정했다.





댓글 남기기