블로그를 운영할 때 신경써야 할 부분은 검색엔진최적화이다. 검색엔진에 잘 노출이 되어야 많은 사람들이 방문을 하게 될 것이고, 방문객이 많아야 매출로 연결되는 고객을 조금이라도 더 많이 확보할 수 있기 때문이다. 하지만 그렇다고 방문객이 무조건 많으면 좋을까? 그렇지는 않다. 방문객은 방문객인데 신뢰를 바탕으로 한 방문객이어야 한다. 반대로도 성립이 되는데 방문객이 신뢰를 갖게 만들어주어야 그 방문객이 고객이 될 것이다.

하지만 보통 블로그 마케팅을 하게 되면 이 부분을 간과하게 된다. 블로그 마케팅 뿐만 아니라 다른 마케팅 채널에서도 무조건 사람들의 눈에만 띄면 된다는 식의 생각은 역효과를 일으킬 수 있다. 눈에 띄어서 들어왔는데 그 안의 내용은 원했던 내용과는 전혀 상관없거나 기분을 불쾌하게 하는 경험을 하게 만든다면 안하느니만 못한 마케팅이 되기 때문이다.
이 부분을 간과하는 또 다른 이유로는 정량적인 측정을 강조하다보니 숫자의 거짓말에 속게 되기 때문이다. 방문객수만을 강조하는 경향이 있다보니 방문객수를 높이기 위해 수단과 방법을 가리지 않게 되는 것이다.
수단과 방법을 가리지 않는 것은 항상 결과가 좋지 않다. 그렇기에 결과를 위해서 수단과 방법을 가려야 한다. 이는 역시 검색엔진최적화에서도 꼭 필요한 부분이다. 혹자는 콧방귀를 뀔지도 모른다. 키워드를 선점하는 사람이 이기는 것이라 생각할지도 모른다. 실제로 그런 생각을 가진 사람들로 인해 검색엔진은 계속해서 알고리즘 개편을 하게 된다.
검색엔진최적화를 생각할 때 최근 많이 사용되는 방법은 제목에 키워드를 반복하는 것이다. 예를 들어 등산용품에 대한 키워드를 선점하기 위해 제목을 “등산용품/등산화/아웃보어/등산복싸게파는곳/고어텍스/예쁜등산복”이란 제목을 사용하는 식이다. 또한 내용에도 같은 키워드를 반복하고 하얀색 글씨로 키워드를 반복하고, 다시 폰트 사이즈를 0으로 해서 보이지 않는 글자를 써서 키워드를 반복하는 식으로 글을 작성한다.
실제로 블로그 마케팅을 운영하는 광고주들을 만나서 이야기를 해 보면 의외로 많은 곳에서 이런 키워드 작업을 당연한 것처럼 생각하고 자랑처럼 이야기하는 경우를 듣게 된다. 서포터즈 블로거들에게 이런 방법을 교육시키고 장려하고 있는 것이다. 이 외에도 내용과는 전혀 상관없는 실시간 검색어를 반복하고, 선정적인 사진이나 동영상을 넣어 방문객을 유도하는 경우도 있다. 특히 병원 쪽에서 이런 마케팅을 주로 하는데, 이는 매우 위험한 마케팅이라 말하고 싶다.
검색엔진최적화를 하기 전에 검색하는 사람이 어떤 생각을 가지고 검색을 할지 우선 생각해보면 쉽게 답이 나온다. 검색하는 사람이 “홍대 맛집”이라고 검색했다면 왜 그 키워드를 사용해서 검색을 했을까? 바로 홍대에서 맛있는 집이 어딘지 찾고 싶기 때문일 것이다. 매우 간단하고 당연한 이야기다. 하지만 “홍대 맛집”으로 검색했는데, 홍대 맛집이 나오는 것이 아니라 홍대에서 제일 맛없는 집이 나오거나 성형외과가 뜬금없이 나온다면 어떻겠는가? 그런 검색엔진은 검색을 제대로 해주지 못하는 검색엔진이고, 검색한 사람은 검색엔진에 대한 신뢰는 물론 그 컨텐츠를 작성한 블로그에 대한 신뢰를 잃게 될 것이다. 만약 그것이 개인블로그라면 그냥 그 개인블로그를 안들어가는 것에서 그치겠지만, 기업블로그라면 그 기업의 브랜드 이미지는 급격히 안좋아질 것이다. 방문객의 불쾌한 경험이 기업 이미지에 그대로 녹아들어가기 때문이다. 병원 블로그들이 현재 진행하는 마케팅이 위험한 것은 병원이 마케팅을 하는 것 자체도 위험하지만 생명을 다루는 (그렇지 않아도 그에 상응하는) 곳의 이미지가 신뢰를 잃게 된다면 그것보다 최악의 마케팅은 없을 것이기 때문이다.
좀 더 근본적으로 생각해보면 검색엔진의 존재 이유에 대해 생각해볼 수 있을 것이다. 검색엔진은 검색했을 때 원하는 결과를 얻을 수 있도록 검색결과를 내 주어야 검색엔진을 유지할 수 있다. 아무리 광고로 얼룩진 검색엔진이라고 해도 발전 방향은 광고를 걷어내고 검색했을 때 순수한 검색 결과를 내놓아야 그 검색엔진이 지속될 수 있을 것이다. 따라서 검색엔진은 알고리즘을 지속적으로 변화시켜 나가는데, 그 변화의 방향은 검색자가 검색을 했을 때 원하는 최적의 답을 내 놓는 방향으로 진화해나갈 수 밖에 없다.
최근에 네이버는 새로운 검색엔진 알고리즘을 선보였다. 바로 리브라(LIBRA)라는 알고리즘을 적용한 것이다. 12월부터 맛집 블로그를 대상으로 점차 범위를 늘려나가고 있는데, 이번에 개선이 되면서 중점을 둔 것은 이용자가 만족하는 더 좋은 콘텐츠가 검색 결과에 잘 반영되도록 하는데에 있다.
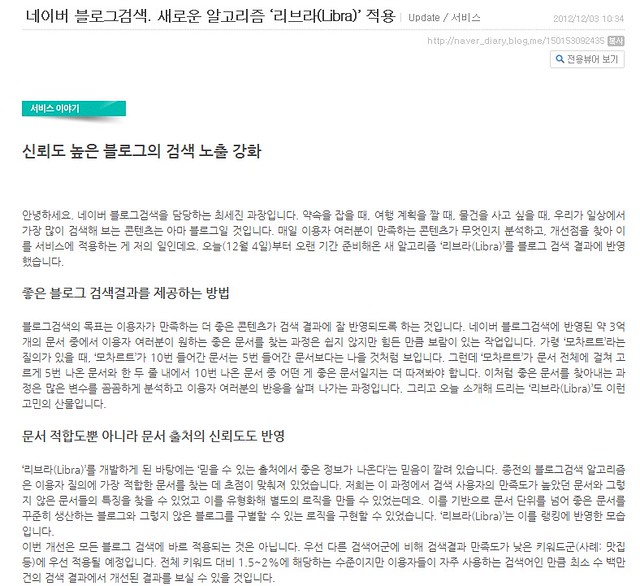
네이버 리브라에서 발표한 좋은 문서와 유해 문서의 기준을 한번 살펴보자.
위의 기준들을 보면 검색엔진이 어떻게 변화해나갈지를 정확히 볼 수 있다. 원문이 보호되는 방향으로 나아가고 있고, 신뢰받을 수 있는 컨텐츠를 작성하는 블로그가 더 잘 노출되는 방향으로 가고 있다. 위에 있는 모든 내용을 한마디로 축약한다면 직접 작성한 진정성 있는 글이 더 잘 노출이 된다고 할 수 있을 것이다.
검색엔진최적화를 하는 가장 좋은 방법은 아이러니하게도 검색엔진최적화를 하지 않는 것이라 할 수 있다. 콘텐츠에 집중하고 공감대를 형성할 수 있는 컨텐츠를 신뢰받을 수 있도록 작성하는 것이 가장 좋은 검색엔진최적화 방법인 것이다.
이미 구글은 네이버의 기준보다 더 엄격한 기준으로 검색결과가 반영되고 있다. 다음은 현재 원문 보호도 되지 않고, 원문을 보호하는 기술조차 가지고 있지 않긴 하지만 (썬도그님의 “총체적 난국에 빠진 다음, 문제 인식조차 안되고 있다: http://photohistory.tistory.com/12683 참조) 다음이 생존하기 위해서 나아갈 방향은 원문이 보호되는 기술을 확보하고 더 좋은 검색 결과를 내놓는 방향으로 변해갈 것은 자명하다.
좀 허무한 결론이라 느낄 수 있지만, 우리가 배워야 할 것은 이미 다 유치원에서 배웠다는 말처럼 기본을 지키는 것이야 말로 가장 빨리 갈 수 있는 방법이기도 하다.
이런 검색엔진의 특성에 맞춰서 앞으로 어떻게 검색엔진최적화를 이룰 수 있는지에 대한 기본적인 내용을 앞으로 살펴보도록 하겠다.






댓글 남기기