카카오는 12일 테크블로그를 통해 자체 개발한 멀티모달(Multimodal) AI 모델인 ‘Kanana-o(카나나-o)’와 ‘Kanana-v-embedding(카나나-v-임베딩)’의 성능 및 연구 성과를 공개했다.
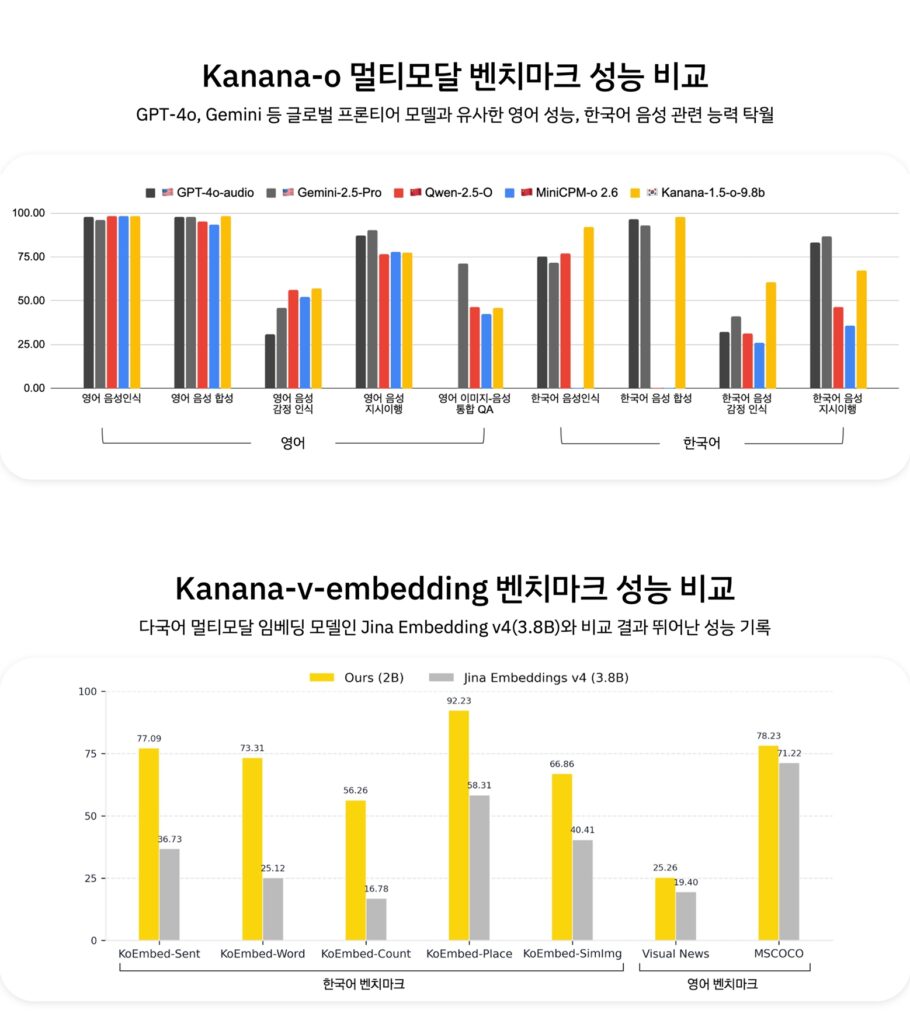
이번에 공개된 ‘Kanana-o’는 텍스트, 음성, 이미지를 동시에 이해하고 실시간으로 답변하는 통합 멀티모달 언어모델이다. 카카오는 기존 모델들이 음성 대화 시 답변이 단순해지는 한계를 보완하여 지시 이행 능력을 강화했다고 설명했다. 이를 통해 요약, 의도 해석, 오류 수정, 형식 변환 등 다양한 과업 수행이 가능하다.
특히 DPO(직접 선호 최적화) 기술과 고품질 음성 데이터를 적용해 억양, 호흡 등 미세한 소리 변화를 학습시켰다. 이를 통해 기쁨, 슬픔 등 상황별 감정 표현이 가능하며, ‘팟캐스트’ 형태의 데이터셋 학습으로 끊김 없는 멀티턴(Multi-turn) 대화를 구현했다. 카카오 측 벤치마크 결과에 따르면 영어 음성 성능은 GPT-4o와 유사한 수준이며, 한국어 음성 인식 및 감정 인식 능력에서는 높은 수치를 기록했다.
함께 공개된 ‘Kanana-v-embedding’은 이미지 기반 검색의 핵심 기술인 멀티모달 임베딩 모델이다. 텍스트와 이미지를 동시에 처리하여 관련 정보를 검색한다. 이 모델은 ‘경복궁’, ‘붕어빵’ 등 한국적 고유명사와 문맥 이해에 강점이 있으며, 오타가 포함된 검색어나 ‘한복 입고 찍은 단체 사진’과 같은 복합적인 조건도 처리할 수 있다. 현재 해당 기술은 카카오 내부 광고 소재 심사 시스템에 적용 중이다.
카카오는 향후 계획으로 모바일 기기 등 온 디바이스(On-device) 환경에서 구동 가능한 경량화 모델 연구와 함께, MoE(Mixture of Experts) 구조를 적용한 고성능 모델 ‘Kanana-2’를 연내 개발할 예정이라고 밝혔다.
김병학 카나나 성과리더는 “단순 정보 나열을 넘어 사용자의 감정을 이해하고 자연스럽게 대화하는 AI를 목표로 한다”며 “한국적 맥락의 이해와 표현력을 지속적으로 높여갈 것”이라고 말했다.





댓글 남기기